C++ Moderne - Les accents
Gérer les accents, et plus particulièrement les caractères spéciaux en informatique est ardu. Voyons ensemble les solutions.


« En C++ pour gérer les accents/l'Unicode il faut utiliser wchar_t »

L'une des idées reçues qui me dérange le plus en C++ est la façon dont il faut gérer les "accents", ou de façon plus générale les caractères spéciaux.
Un brin d'histoire.
Revenons tout d'abord sur la façon dont les applications (au sens large, donc site webs y compris) gèrent les caractères, ils utilisent ce qu'on appelle un jeu de caractères ("Character sets" en anglais).
En effet, les ordinateurs étant de grosses calculatrices dotées de mémoire, ils ont beaucoup de mal à gérer le texte humain, et de façon générale tout ce qui n'est pas un nombre.
Ainsi, les premiers ingénieurs informaticiens[1] se sont retrouvés confrontés aux choix suivants : ou bien ils apprenaient à l'humanité à communiquer en binaire[2], ou bien ils apprenaient aux ordinateurs à communiquer en anglais (et à terme, toutes les autres langues).
Après bien des réflexions, il est apparu qu'il était plus facile de faire évoluer les ordinateurs que l'humanité, et nos chers ingénieurs ont dû trouver un moyen de représenter du texte informatiquement.
La solution qui a été retenue a été d'établir des tables de correspondance entre les nombres et les lettres, ainsi nous dirons que la lettre a minuscule correspond au nombre 97, le symbole espace au nombre 32, etc.
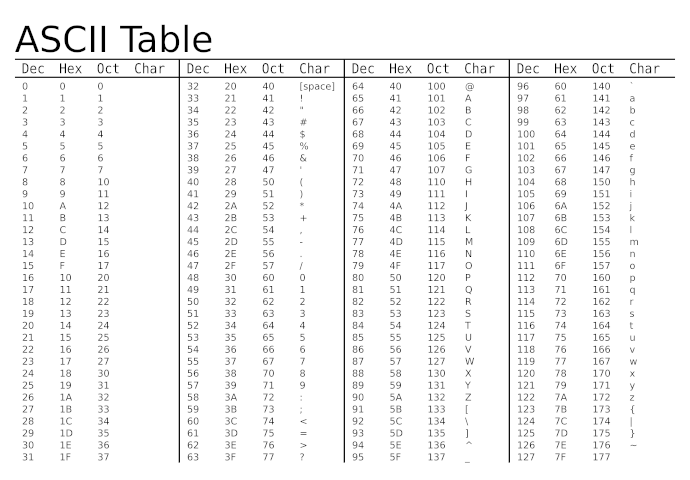
Ainsi est née la table ASCII dans les années 60, encore beaucoup utilisée aujourd'hui. Cette table de correspondance couvre l'alphabet latin ainsi que quelques caractères spéciaux, couvrant une très large partie des usages américains sur 7bits.
Seulement voilà, il existe sur cette planète une proportion non-négligeable de personnes n'étant pas américaines (un petit ~95,74%) ou n'ayant pas l'anglais comme langue maternelle (~95,1%), et il fallait bien les prendre en considération un jour.
Je vais résumer la suite de l'histoire: de nombreuses tables de codage sont apparues dans les années qui ont suivi, comme le très connu Latin 1, le Latin 8 étendu, le Windows 1250, etc.
Ces tables de codage ont en commun le fait qu'elles profitent du fait que la table ASCII soit codée sur 7 bits et que les ordinateurs utilisent des octets ("byte" en anglais[3], sur 8 bits), laissant donc un bit supplémentaire pour rajouter des caractères (permettant de doubler la capacité actuelle, donc 127 entrées supplémentaires).
Ainsi pendant un temps[4], la plupart des sites web fournissaient du contenu en précisant quel codage étendu ils utilisaient (la locale), que le navigateur se devait de gérer sous peine d'être incapable d'afficher le contenu de la page.
Unicode, le (les?) sauveur(s?)
Évidemment, l'idée d'une table de codage capable de prendre en compte l'entiereté des symboles existants[5] arriva très rapidement, mais la mémoire et la bande passante coûtaient plus cher à l'époque. C'est pour ça qu'un tel encodage mit du temps à arriver, mais au début des années 1990 deux initiatives finirent par pointer le bout de leur nez, d'un côté l'Unicode et de l'autre l'Universal Coded Character Set (ou UCCS).
Les deux initiatives avaient pour objectif commun de ne plus se prendre la tête avec la notion de locale et de gérer tout avec un seul et même encodage.
La solution initialement proposée par Unicode était de faire grosso-modo une table ASCII internationale sous stéroides, tenant sur 16 bits et donc capable de représenter un total de 65,536 caractères différents, bien peu comparé aux 679,477,248 caractères[6] possible de l'UCCS (aussi appelé ISO 10646).
Une des différences entre les deux était qu'Unicode définissait des propriétés pour chaque caractère, comme le sens de lecture, la catégorie, la lettre minuscule/majuscule correspondant, là où l'UCCS se contentait d'une association entre une valeur numérique et un caractère.
Mais la différence principale entre les deux tenait dans leur représentation binaire, là où Unicode se voulait simple avec un type de caractère sur 16bits, l'ISO-10646 prévoyait plusieurs encodages différents (façons d'écrire les nombres correspondant aux caractères) afin de satisfaire les besoins de consommation mémoire, cette dernière coûtant encore très cher à l'époque.
En effet, il existait trois façons de représenter les caractères en ISO-10646 :
- l'UCS-4 : l'approche bête et méchante qui consiste à encoder le caractère sur quatre octets, quitte à ne pas utiliser tous les bits.
- l'UCS-2 : l'approche "on satisfait la majorité", qui consiste à stocker le caractère sur deux octets et tant pis pour ceux qui ne rentrent pas dedans. Cette approche qui ne permet que de gérer le BMP (Basic Multilingual Plane), un ensemble de caractères commun à beaucoup de langues et suffisant pour pas mal de cas (retenez-le, ce sera utile pour la suite).
- l'UTF-1 : un stockage à taille variable selon le caractère stocké, l'idée était d'utiliser un octet si ça suffisait, deux sinon, puis trois, etc. (jusqu'à cinq).
Les compagnies informatiques de l'époque craignaient la complexité de l'ISO-10646, à taille et encodage variable, et lui ont préféré l'Unicode, à un seul encodage à taille fixe.
Seulement voilà, il n'a pas fallu beaucoup de temps avant de s'apercevoir que 65,536 caractères pour l'humanité entière, c'est peu (quand bien même on avait réussi à caser les caractères japonais, chinois et coréens dans le BMP) et il devint nécessaire d'aborder une solution.
Ironiquement la solution vint de l'ISO-10646, rejetée initialement pour sa complexité, qui s'unifia avec Unicode dans les années qui suivirent, l'UCS-4 devint l'UTF-32 et l'encodage 16bits original d'Unicode devint l'UTF-16, fonctionnant avec un mécanisme similaire à l'UTF-1 lui permettant de s'étendre sur deux caractères de 16bits en cas de besoin (via le mécanisme des surrogate pair[7]).
L'UTF-8, l'encodage Unicode le plus répandu au monde actuellement, fit son apparition peu après, fonctionnant selon la même idée que l'UTF-1 : les caractères sont écrits sur une suite de 1 à 4 octets (6 initialement mais revu à la baisse) selon le caractère que l'on cherche à écrire, avec une compatibilité directe avec l'ASCII de base.
Ce dernier point est très important, il signifie que l'UTF-8 et l'ASCII ont exactement la même représentation à partir du moment où on reste sur les premières 127 valeurs, on en reparlera juste après.
Et wchar_t dans tout ça ?
Le type wchar_t (wchar pour "wide character") fait partie de la norme C89 originale du C, et existe donc en C++ aussi. Son objectif était de permettre de gérer tous les "codes" de n'importe quelle locale supportée par le système avec un seul type.
Type wchar_t is a distinct type whose values can represent distinct codes for all members of the largest extended character set specified among the supported locales (22.3.1).
C++ [basic.fundamental] 3.9.1/5
Qu'est-ce que cela signifie ?
Concrètement, cela signifie tout d'abord que wchar_t dépend de la locale pour son encodage, tout comme pour l'ASCII étendu qu'on a vu plus haut. Cela signifie également que son interprétation dépend du système, et n'est donc pas portable.
Il y a une idée reçue qui veut que wchar_t ajoute le supporte de l'Unicode aux langages, mais c'est faux, Unicode n'est apparu qu'en 1991 alors que le type de caractère étendu existait depuis quelques années déjà.
On arrive alors sur la raison pour laquelle il ne faut pas utiliser wchar_t dans ses programmes : ce n'est pas forcément de l'Unicode et sa définition dépend du système, le rendant non-portable.
Par exemple sous Windows, wchar_t représente de l'UTF-16 (UCS-2 précédemment), sous Linux (et de façon générale, tout ce qui n'est pas Windows) cela représente de l'UTF-32. Les deux sont incompatibles.
Une autre idée reçue sur wchar_t est qu'il permet, contrairement aux encodages dits multi-caractères (comme l'UTF-8 et l'UTF-16), de faire la correspondance directe entre un wchar_t et un caractère (facilitant le traitement informatique), mais c'est incorrect. Sous Windows un wchar_t est utilisé par le système pour représenter de l'UTF-16 (signifiant donc qu'un caractère peut être stocké sur deux wchar_t).
Voyons un exemple :
On l'a vu, wchar_t peut stocker plusieurs encodages, on peut même se retrouver à stocker de l'UTF-8 à l'intérieur, mais ce qui va nous intéresser ici c'est l'encodage utilisé par le système.
Et la façon la moins compliquée que j'ai pu trouver[8] a été de créer des dossiers dans mon arborescence comportant les caractères en question et ensuite de retrouver le nom de ces dossiers au travers de l'API Windows.
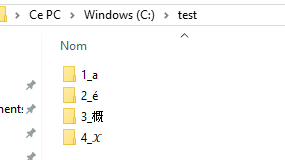
Attention, je ne garanti aucunement la beauté du code qui peut suivre :
#include <cwchar>
#include <iostream>
#include <string>
#include <windows.h>
int main()
{
WIN32_FIND_DATAW ffd;
HANDLE hFind = FindFirstFileW(LR"(C:\test\*)", &ffd);
if (hFind != INVALID_HANDLE_VALUE)
{
do
{
std::wstring str(ffd.cFileName);
if (str[0] >= L'0' && str[0] <= L'9')
std::cout << (str[0] - L'0') << ": " << str.size() - std::wcslen(L"0_") << std::endl;
}
while (FindNextFileW(hFind, &ffd) != 0);
FindClose(hFind);
}
}
L'idée donc ici est de récupérer la liste des dossiers présents dans mon dossier de test, de s'assurer qu'ils commencent bien par un chiffre (permettant de ne pas traiter les dossiers spéciaux . et ..[9]), d'afficher le chiffre correspondant en question pour être sûr et enfin soustraire une taille fixe (le chiffre et le caractère underscore) afin de n'obtenir qu'une seule réponse : le nombre de wchar_t nécessaires pour représenter le caractère.
Bien sûr, ici j'aurai pu afficher simplement le nom du dossier dans la console de Windows, mais cette dernière n'aime pas les caractères spéciaux (ils peuvent aller jusqu'à planter l'affichage) et bien qu'il soit possible de la configurer pour que cela fonctionne bien j'ai préféré opter pour une solution facilement reproductible chez chacun qui souhaiterait tester ça chez lui.
Les résultats sont les suivants :
1: 1 (a)
2: 1 (é)
3: 1 (概)
4: 2 (𝒳)
Notez que j'ai rajouté le caractère correspondant à la main pour faciliter la compréhension, il n'apparaît pas en sortie du programme.
On voit donc que les trois premiers caractères ne nécessitent qu'un seul wchar_t pour être représentés, ceux-ci faisant partie du BMP, mais que le quatrième lui (le X mathématique caligraphié) en nécessite deux, on parle donc ici de surrogate pair.
Conséquence de tout ceci, votre programme ne peut pas partir du principe qu'un wchar_t ne représente qu'un seul caractère, et par conséquent, que std::wstring::size renverra bien le nombre de caractères.
J'insiste sur ce point car beaucoup de programmes font la bêtise de traiter wchar_t pour ce qu'il n'est pas (même l'interface graphique de Windows a du mal et me permet notamment de copier-coller la moitié du caractère seulement).
Alors vous pourriez me répondre, en arborant votre tee-shirt avec un manchot célèbre imprimé dessus : "Oui mais ça c'est un problème qui ne concerne que Windows, tous les autres systèmes n'ont pas ce problème".
Et vous auriez partiellement raison, cependant en la matière la seule parole qui fasse autorité est la sacro-sainte norme C++, et celle-ci n'apporte absolument pas cette garantie.
Car quand bien même vous vous limiteriez à ce qui est supporté sous Linux (par exemple), vous ne pouvez pas prévoir devoir un jour porter votre application sur une autre plateforme (qui n'existe peut-être pas encore), et la seule contrainte qui sera respectée par les compilateurs sur cette nouvelle plateforme sera la norme C++.

Surtout qu'en plus, nous allons voir qu'il existe une solution portable et devenue standard de facto ces dernières années.
UTF-8 le sauveur
l'UTF-8 est l'encodage le plus utilisé actuellement sur le web représentant, à l'heure où j'écris ces lignes, pas moins de 92% des sites web dans le monde, ce qui fait quand même un sacré paquet d'utilisateurs.
Pour les autres applications (dont celles qui nous intéressent, les applications desktop à proprement parler), il y a tout ce qui est Windows et tout ce qui n'est pas Windows.
Je vais simplifier en partant du principe que si vous n'êtes pas sous Windows, vous êtes alors sur une plateforme Unix-like implémentant POSIX[10] auquel cas l'UTF-8 est déjà l'encodage recommandé pour le système et le plus utilisé.
Dans le cas contraire, pas de soucis ! Il est parfaitement possible d'utiliser également UTF-8 dans votre programme même si ce n'est pas l'encodage de votre système, et c'est ce que je vous recommande.
Mais du coup, comment faire pour utiliser de l'UTF-8 en C++ ? La bonne nouvelle c'est que vous n'avez presque rien à changer ! En effet std::string est tout à fait capable de stocker de l'Unicode car comme on l'a vu, l'UTF-8 se gère par octets (via le type char).
Il vous suffit donc d'avoir de l'UTF-8 dans la dite chaîne, ce qui peut se faire de plusieurs façons.
Enregistrer ses fichiers en UTF-8
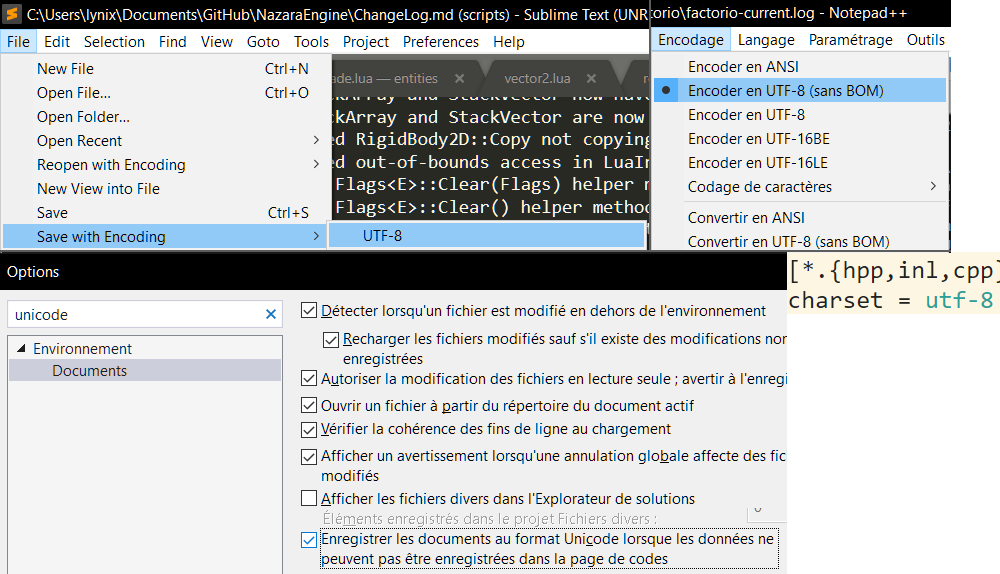
La façon la plus simple et transparente d'intégrer de l'Unicode dans ses programmes consiste à enregistrer ses fichiers en UTF-8, enregistrant directement les caractères spéciaux de la bonne façon. Cela ne demande même pas au compilateur de savoir qu'il traite de l'UTF-8. En effet lorsque vous écrivez :
std::string str = "Héhé !";
le compilateur verra :
std::string str = "Héhé !"; //< Représentation en Latin-1 de caractères spéciaux UTF-8
et cela lui ira très bien car il s'agit d'une chaîne de caractère parfaitement valide.
Cela signifie que cette façon de faire fonctionne également en C, en C++03 et même dans d'autres langages[11], l'important étant surtout la capacité des fonctions d'affichages à gérer de l'UTF-8.
C'est la façon de faire que je vous recommande. La configuration dépendra des logiciels que vous utilisez, néanmoins EditorConfig (supporté nativement/via un plugin pour tout environnement de développement qui se respecte) vous permet de préciser votre souhait via un simple :
charset = utf-8
Que demander de plus ?
Petite remarque : certains logiciels vous proposeront de l'UTF-8 avec/sans BOM. Le BOM (pour Byte Order Mark) est un ensemble de trois octets placés en début de fichier permettant d'identifier l'UTF-8 comme encodage.
En l'absence de celui-ci l'UTF-8 ne sera détecté qu'au premier caractère spécial (ce qui peut être problématique si votre fichier n'en possède aucun, car pour rappel l'UTF-8 est strictement équivalent à l'ASCII en l'absence de caractères spéciaux).
L'opinion majoritaire semble être de ne pas mettre de BOM, même si le débat fait rage. Pour ma part je vous recommande d'éviter de le mettre à partir du moment où vous pouvez configurer vos logiciels pour enregistrer vos fichiers en UTF-8 par défaut.
Utiliser la notation hexadécimale
Si vous préférez avoir une solution indépendante de l'encodage de votre fichier, il est également possible (depuis le C++11) d'insérer des caractères Unicodes directement depuis leur valeur hexadécimale (trouvable par exemple ici) de la façon suivante :
std::string str = u8"H\u00E9h\u00E9"; //< "Héhé"
Le préfixe u8 en début de chaîne spécifie l'encodage désiré ainsi que le type sous-jacent char (il est également possible d'utiliser u"" pour de l'UTF-16 via char16_t, U"" pour de l'UTF-32 via char32_t et L"" pour du "spécifique à la plateforme pas beau" via wchar_t).
MaJ 2023: Attention, en C++20 et plus, le préfixe u8 ne spécifie plus le type char mais char8_t (et nécessiterait donc un std::u8string ici).
Je vais essayer de me chauffer pour dire tout le "bien" que je pense de ce changement dans un nouvel article.
Ensuite, lorsque vous désirez écrire un caractère spécial vous écrivez \u suivi de quatre chiffres hexadécimaux (de 0 à F) indiquant votre caractère (il est également possible d'utiliser \U avec huit chiffres hexadécimaux en cas de besoin), tous les autres caractères ASCII s'écrivent normalement.
Cette façon de faire à le mérite d'être la plus portable, vous pouvez ainsi copier-coller du code vers n'importe quel endroit et vous assurer que votre Unicode y survivra, en revanche elle nuit fortement à la lisibilité et l'écriture.
Utiliser des fichiers externes
La façon la plus intelligente de faire selon moi est de n'avoir aucune, dans la mesure du possible, chaîne Unicode au sein de votre programme : utilisez l'anglais pour les messages/erreurs internes, commentaires et sortez tous vos messages affichables/accessibles à l'utilisateur dans plusieurs fichiers externes, typiquement un par langue, que votre application pourra charger à son lancement.
Ainsi votre application pourrait utiliser quelque chose comme :
class Localization
{
public:
Localization(const std::string& filename);
const std::string& Translate(const std::string& key);
private:
std::unordered_map<std::string, std::string> m_translations;
};
Localization loc("fr_FR.json"); //< Point bonus si paramétrable en dehors du code source
std::cout << loc.Translate("HELLO_WORLD") << '\n';
Avec fr_FR.json (enregistré au format UTF-8) contenant par exemple :
{
"HELLO_WORLD": "Héhé, salut tout le monde !"
}
C'est un peu primitif mais vous voyez l'idée, l'avantage étant bien sûr de permettre le portage de votre programme vers une nouvelle langue sans avoir besoin d'avoir accès au code source ou de devoir le recompiler.
À noter que si vous utilisez Qt, le framework fournit une solution clé en main pour cela.
Quelques précautions à prendre
Note importante : à partir d'ici dans l'article je vais parler de "caractère Unicode" (Unicode codepoint en anglais), il s'agit d'une valeur numérique existant dans la table Unicode, mais pas forcément d'un caractère affichable comme nous le verrons plus loin.
Bien maintenant que nous disposons de chaînes de caractères stockant de l'Unicode (et plus précisément de l'UTF-8), il faut que vous sachiez que cela à ses implications. Ainsi si vous stockez une chaîne UTF-8 dans un std::string[12], il vous faut prendre certaines choses en compte :
size() ne correspond plus au nombre de caractères
Comme on l'a vu, UTF-8 est un encodage à taille variable, ce qui signifie qu'un caractère peut occuper entre un et quatre char, par exemple :
std::string str = "Héhé"; // "Héhé" en Latin-1
std::cout << str.size() << '\n'; // Affiche 6 et non pas 4
L'indexation/l'itération ne fonctionne plus
Avec l'ASCII / l'UTF-32, str[2] vous donnera le troisième caractère de la chaîne.
Avec l'UTF-8 ça pourra être un morceau du premier, un morceau/le début du second ou encore un le début du troisième caractère.
std::string str = "Héeè"; // "Héeè" en Latin-1
std::cout << str[2] << '\n'; // Affiche ©
Non seulement nous n'avons pas indexé correctement la chaîne mais en plus nous ne récupérons qu'un morceau de caractère incomplet !
Oubliez std::tolower/std::toupper
S'il est trivial en ASCII de faire la conversion entre les majuscules et les minuscules, en Unicode cela demande de stocker la correspondance dans une grosse table, et vous trouverez encore des langues où la gestion est plus complexe encore et où cela ne suffira probablement pas.
Mieux vaut éviter d'avoir besoin de cette fonctionnalité, ou utiliser des bibliothèques spécialisées comme nous allons le voir.
Utilisez de l'UTF-32 en cas de besoin
Si vous avez souvent besoin d'indexer dans une chaîne de caractère Unicode, il peut être intéressant de la stocker temporairement au format UTF-32, vous permettant une gestion plus simple et potentiellement plus rapide (pensez à mesurer l'impact de votre programme).
La conversion entre l'UTF-8 et l'UTF-32 est triviale et peut se faire facilement surtout si vous ...
Utilisez des bibliothèques
Il existe de nombreuses bibliothèques capables de traiter tous les problèmes que je viens de citer, comme par exemple utf8cpp, utf-cpp, utf8.h et bien d'autres.
Ces bibliothèques vous permettent de manipuler assez aisément l'UTF-8 en vous permettant par exemple d'itérer sur les caractères Unicode directement, en vous donnant la taille, de vérifier la validité de l'encodage, de convertir de l'UTF-8 vers autre chose ou inversement, etc.
Cependant, la gestion correcte de l'Unicode est horriblement complexe, et il n'existe à ma connaissance qu'ICU qui le propose, au prix d'une intégration complexe et d'une certaine surcharge pondérale (liée à toutes les données qu'il faut stocker pour ce faire).
Et ce n'est pas tout, je vous ai caché deux autres détails sur l'Unicode qui expliquent pourquoi sa gestion correcte est abominable.
- Tous les glyphes (caractères affichés) ne correspondent pas à un caractère Unicode, par exemple l'emoji "👌" (
\u1F44C) correspond bien à un seul caractère Unicode mais "👌🏾" en nécessite deux (\u1F44C\u1F3FE), soit le caractère "👌" suivi de " 🏾 " ("couleur marron") [13]. - Un même glyphe peut s'écrire de plusieurs façons différentes, par exemple "é" peut soit correspondre au simple caractère Unicode (
\u00E9) soit à la composition de la lettreeclassique avec le caractère "Diacritique accent aigu" "◌́" (\u0x0301). Ainsi\u00E9ete\u0301sont supposés représenter le même symbole.
Quant à l'affichage correct de l'Unicode, c'est encore une autre paire de manche. Par exemple il existe un caractère Unicode non-affichable dont le rôle est de changer l'ordre d'écriture de droite à gauche.
La bibliothèque de référence pour gérer l'affichage de l'Unicode est un autre mastodonte utilisé par virtuellement tous les navigateurs webs et nombre de frameworks: HarfBuzz.
N'essayez pas de gérer parfaitement l'Unicode
Dans cet article je vous ai présenté des façons de gérer l'Unicode simplement qui, même si elles sont imparfaites, sont largement suffisantes pour une utilisation classique. Comprenez bien que bon nombre d'applications éprouvées aujourd'hui se cassent encore les dents sur la gestion correcte de l'Unicode.

Ainsi donc, tant que votre souhait est juste d'afficher des caractères spéciaux et gérer des cas d'utilisation classiques alors vous devriez vous en sortir avec les bibliothèques simples présentées plus haut. Si vous avez besoin d'avoir une gestion plus fine et correcte de l'Unicode, je vous recommande fortement d'utiliser un framework existant (type Qt) plutôt que les bibliothèques par défaut type ICU et HarfBuzz.
Une gestion simple de l'Unicode suffit pour la majorité des programmes, jusqu'au moment où ça ne suffit plus.
Et UTF-16 alors ?
J'ai très peu parlé de l'UTF-16 dans cet article. S'il apparait au premier abord comme un compromis raisonnable entre l'UTF-8 et l'UTF-32, il est en réalité le pire des deux mondes et combine surtout leurs défauts.
En effet tout comme l'UTF-8 il est à taille variable (et donc pas indexable) et tout comme l'UTF-32 il n'est pas directement compatible avec l'ASCII, prend obligatoirement au moins deux octets par caractère et son interprétation dépend du boutisme (endianness en anglais), faisant donc apparaître deux variantes pour chaque encodage: UTF-16BE, UTF-16LE, UTF-32BE et UTF-32LE.
Le seul avantage de l'UTF-16 semble être de prendre légèrement moins de place que l'UTF-8 pour les caractères asiatiques (deux octets au lieu de trois), mais le gain de place semble marginal, surtout une fois la compression utilisée.
Pour plus d'informations je vous invite à lire et partager le manifeste UTF-8 Everywhere qui oppose les avantages et inconvénients des encodages Unicodes et explique la situation sans doute mieux que cet article entier ne l'a fait.
Et pour l'affichage des caractères spéciaux dans la console ?
Si vous êtes sous Linux, comme vous l'avez déjà certainement remarqué, tout fonctionne sans le moindre effort, l'UTF-8 étant la norme.
Sous Windows en revanche, les choses se corsent sévèrement. La méthode la plus simple pour y parvenir consiste, via le registre, à changer l'encodage par défaut utilisé par la console.
Le gros défaut de cette solution est bien évidemment qu'il faut intervenir sur le système pour avoir une console acceptable, donc si vous comptez distribuer votre programme il vaut mieux qu'il fasse ça lui-même.
Si vous ne souhaitez pas toucher aux paramètres de la console, il est également possible de laisser Windows faire la conversion, une possibilité est la fonction système WriteConsoleW dont une utilisation est décrite ici.
Une autre possibilité est de paramétrer la sortie de la console en UTF-16 (à l'aide de _setmode et d'utiliser les fonctions standard "wide" (telles que std::fputws), c'est par exemple ce que je fais dans Burg'war.
Quant à la saisie, j'avoue ne pas m'être posé la question, ça pourrait faire l'objet d'un prochain article... ;-)
Dans tous les cas il vous faut toucher à l'API Win32 (l'API système de Windows) et utiliser des wchar_t (il vous suffit de convertir l'UTF-8 en UTF-16 pour en obtenir), je ne recommande pas à tout le monde de se prendre la tête avec ça, les programmes sérieux sous Windows utilisant de toute façon une interface graphique autre que la console.
En résumé, évitez d'avoir besoin d'accents dans vos programmes console sous Windows, généralement ça ne sert que pour l'apprentissage et cela n'en vaut pas la peine.
TL;DR
Même si j'ai essayé d'être complet dans cet article, sachez que l'Unicode est un sujet vraiment complexe et que sa gestion demande beaucoup de travail. Déléguez-le à un framework existant ou simplifiez vos besoins, il y a de bonnes chances qu'il existe un cas d'utilisation que vous ne gériez pas correctement.
Après tout il s'agit ici de gérer correctement toutes les langues de l'humanité.
Mon conseil est donc, pour le C++, d'utiliser une bibliothèque légère capable de considérer les caractères Unicode dans une chaîne UTF-8 (j'utilise personnellement utf8-cpp), de traîter toutes vos chaînes en UTF-8 (ou temporairement en UTF-32 en cas de traitement conséquent demandant une indexation fréquente) et de faire la conversion au dernier moment vers ce que demande l'API de votre choix (et comme la plupart fonctionnent justement avec de l'UTF-8, vous serez déjà prêts).
J'insiste, lisez et partagez le manifeste UTF-8 Everywhere, et si cet article vous a plu n'hésitez pas à le partager et/ou commenter ;)oct
Ce qui aurait dû ressembler à quelque chose comme ceci : https://www.youtube.com/watch?v=Hy8kmNEo1i8 ↩︎
Le mot "octet" existe également en anglais avec le même sens, mais "byte" est le plus utilisé. La différence entre les deux est qu'historiquement un byte ne faisait pas forcément 8 bits (et pouvait en faire 7, 8, 9, ...). Aujourd'hui le terme est presque exclusivement utilisé pour parler d'une combinaison de 8 bits. ↩︎
Je vous parle d'un temps que les moins de quinze ans ne peuvent pas connaîtreeuh. ↩︎
Oui, les emojis aussi... ↩︎
La représentation de l'UCCS prévoyait 2^31 caractères mais certains octets correspondant aux caractères de contrôles de la table ASCII ne devaient apparaître pour des raisons de sécurité d'interprétation. ↩︎
On va en reparler, mais une surrogate pair est une paire de caractères UTF-16 fonctionnant ensemble pour étendre la capacité de représentation au-delà des 16bits initaux. L'idée est que le premier caractère indique si oui ou non il est complété par le second caractère juste après lui. ↩︎
Cela signifie qu'il existe très certainement une façon plus simple de faire ça. ↩︎
Ces dossiers n'en sont pas vraiment mais permettent de représenter respectivement le dossier courant et le dossier parent dans une arborescence. ↩︎
Et il y a vraiment très peu de chances que vous soyiez sur une plateforme non Unix-like (autre que Windows) et que vous ayez besoin de gérer l'Unicode. ↩︎
Exemple : le Lua avec Garry's Mod. ↩︎
Ou tout autre conteneur de char non spécifiquement conçu pour la gestion de l'UTF-8, y compris std::u8string (malgré son nom), disponible à partir du C++20. ↩︎
Information trouvable notamment sur https://emojipedia.org/emoji/👌🏾/. ↩︎