Concevoir son propre protocole réseau par-dessus UDP - Connexion, fiabilité et intégrité
Dans cet article on discute ensemble de la façon dont on peut concevoir un protocole par-dessus UDP (destiné par exemple au jeu vidéo) avec les principes les plus importants.

Comment concevoir un protocole fiable avec connexions à partir d'un protocole non-fiable et sans connexion ?
Sommaire
- 1. Introduction
- 2. Connexion, fiabilité et intégrité
- 3. MTU et congestion
- 4. Le problème du NAT
- 5. Attaques et chiffrement
- 6. Conclusion
Dans cette section, nous allons aborder les trois aspects les plus importants pour la création d'un protocole par-dessus UDP.
Pour rappel, UDP est à la base :
- Un protocole non-connecté (chacun envoie des paquets à qui il le veut sans accord préalable).
- Un protocole non-fiable (un paquet peut être perdu).
- Un protocole non-ordonné (les paquets peuvent arriver dans le désordre).
- Un protocole assurant peu l'intégrité des données (les paquets peuvent être corrompus).
Avant d'utiliser ce protocole vous voudrez donc des garanties supplémentaires, généralement toutes celles que je vais vous présenter, dépendant de votre cas d'utilisation.
Vous pourrez aussi, selon votre besoin, vouloir vous baser plutôt sur TCP, je vous renvoie à ma série sur le réseau dans le jeu vidéo qui possède un article comparant TCP et UDP.
Plongeons-nous dans le vif du sujet : si vous souhaitez faire votre propre protocole en utilisant UDP, les points suivants sont importants :
Les connexions
Les paquets UDP peuvent être envoyés à n'importe qui et de n'importe qui. Il nous faut donc établir un processus de connexion pour avoir l'assurance que l'on discute bien avec quelqu'un ayant souhaité nous parler.
Dans le cas de TCP, un three-way handshake est effectué, c'est-à-dire que trois paquets devront être échangés avant que la connexion ne soit considérée comme établie :
- Client -> Serveur : paquet de demande de connexion.
- Serveur -> Client : paquet de demande de confirmation de la connexion (le client considère la connexion ouverte à la réception de ce paquet).
- Client -> Serveur : paquet de confirmation de la connexion (le serveur considère la connexion ouverte à la réception de ce paquet).
Ce processus nous permet de nous assurer côté serveur que le client nous a bien demandé une connexion grâce au fait qu'il ait répondu (ce qui ne se serait pas produit en cas d'usurpation d'adresse IP) et d'établir quelques données initiales (dans le cas de TCP par exemple, des numéros de séquence de départ).
Il va ensuite nous falloir un moyen de différencier les clients connectés selon les paquets reçus. En effet avec UDP, contrairement à TCP, vous ne possédez pas une socket par client, vous disposerez généralement d'une seule socket d'écoute (dite "socket serveur") qui recevra l'intégralité des paquets émis par tous vos clients[1].
À chaque fois que vous recevrez un paquet, en plus de son contenu, vous récupérerez l'adresse IP d'émission ainsi que le port de réponse.
Votre serveur va donc devoir être en mesure, pour chaque paquet reçu, d'identifier le client connecté à l'origine de ce paquet, avec bien sûr pour exception le paquet de connexion.
De façon classique cela se fait avec le combo IP d'expédition + port[2], nous verrons plus tard qu'à cause de l'IP spoofing et des éventuelles attaques (type MITM) cela est très insuffisant pour identifier et authentifier un client, mais nous pouvons nous en contenter pour l'instant.
Cependant, si vous souhaitez un tout petit peu plus de sécurité, vous pouvez échanger des nombres secrets (générés aléatoirement) lors de la connexion. Ceux-ci, renvoyés avec chaque paquet permet d'identifier avec un tout petit peu plus de certitude un client. Mais surtout vous pouvez vous servir de ces nombres secrets pour séquencer vos paquets, si vous prenez N et M comme nombres aléatoires à la connexion, vous pouvez décider que chaque paquet envoyé du client au serveur va incrémenter N, et chaque paquet envoyé du serveur au client, M.
C'est justement ce que fait le protocole TCP, nous en reparlerons dans la section sur la fiabilité.
Et du coup une fois la connexion établie, il faut s'assurer qu'elle reste active (plus particulièrement avec UDP à cause de ce qu'on appelle le NAT dont on discutera dans un chapitre ultérieur). Cela se fait simplement en forçant l'envoi d'un paquet (dans un sens comme dans l'autre) si rien n'a été envoyé depuis un certain temps (assez court en général).
Je vous recommande d'envoyer un paquet dit de "ping" si rien n'a été envoyé à un client (ou vers le serveur) depuis 500 millisecondes.
Détecter les connexions mortes devient alors assez simple : si aucun paquet n'a été reçu depuis un certain temps alors nous considérerons la connexion comme ayant expirée (timed out) et n'existant tout simplement plus. (pour la durée mettons quelques dizaines de secondes, 20-30s est une bonne valeur)
Reste alors à gérer la déconnexion volontaire qui se fait simplement en envoyant un paquet spécifique, cela suppose que vous êtes en mesure de différencier les paquets de données des autres. Je vous recommande un octet au début de votre paquet indicant sa nature relative à votre protocole, par exemple on peut dire que les entiers de 0 à 2 correspondent aux paquets de connexion, que 3 représente un ping, 4-5 une demande et une confirmation de déconnexion et 6 un paquet de donnée applicative.
Bien entendu, libre à vous d'avoir les valeurs que vous voulez ou de stocker ça différemment.
On verra un peu plus loin que ce que je vous ai expliqué ici est simpliste et largement insuffisant en terme de sécurité : un attaquant pourrait écouter la connexion et repérer les nombres aléatoires que vous échangez, ou pire, se placer entre vous et le serveur et modifier les paquets qui transitent entre les deux.
Pour régler ces problèmes il nous faudra ajouter une couche de chiffrement, ce que nous verrons dans le dernier chapitre de cette série.
Nous verrons aussi que les implémentations traditionnelles du processus de connexion (en plusieurs paquets) sont sujettes aux attaques DoS (Denial of Service), là encore il existe des solutions.
Mais pour l'instant je vous recommande d'oublier ce genre de choses et de vous concentrer sur la conception d'un protocole fonctionnel, c'est déjà assez compliqué comme ça. :-)
L'intégrité de vos paquets
Internet est un endroit dangereux pour tout paquet qui aurait le malheur de s'y aventurer. En effet, en plus des paquets perdus, dupliqués et retardés il est aussi possible que ceux-ci arrivent correctement mais avec des données différentes du début de leur périple. C'est la corruption.
Cela peut se produire lorsque la transmission d'un routeur à l'autre subit des problèmes (câbles défectueux, ondes radios subissant des interférences, etc.) et en général les routeurs eux-même vont réussir à le détecter et préférer perdre le paquet que de le transmettre en sachant ses données compromises, mais il reste une probabilité faible que cette corruption finisse par atteindre votre application.[3]
Pour se protéger de la corruption, on intègre au paquet un nombre "représentant" le contenu du paquet, ce qu'on appelle une somme de contrôles (checksum).
L'idée étant que lorsqu'à la réception du paquet, le destinataire va recalculer la somme de contrôle et la comparer à celle présente dans le paquet, si les sommes correspondent alors l'intégrité du paquet est assurée.
Pour mieux comprendre, vous pouvez vous représenter ce nombre comme étant une simple addition de tous les octets de votre paquet, si un octet change alors la somme changera (Bien évidemment c'est une vision simpliste : si un octet est incrémenté et un autre décrémenté, la somme restera identique et la corruption passera inaperçue.
C'est pour cette raison que les algorithmes qu'on utilise sont conçus pour maximiser les chances qu'une corruption aléatoire change forcément notre somme de contrôle).
Alors, normalement le protocole UDP intègre déjà une somme de contrôle dans chacun de vos paquet (dans l'en-tête UDP) à votre insu, et le mécanisme de réception rejette les paquets détectés corrompus.
Cependant il y a deux problèmes :
- Cette somme de contrôle est un nombre 16bits (ce qui est insuffisant).
- En IPv4, son calcul est facultatif.
Impossible donc de s'y fier, vous devrez donc penser à rajouter votre propre somme de contrôle garantissant l'intégrité de vos paquets.
Le principe est simple : on ajoute à chaque paquet un champ nommé checksum (généralement un nombre 32bits) qui contiendra le résultat d'un algorithme de calcul de somme de contrôle (CRC32 est un choix courant) appliqué à tout le reste du paquet.
Lorsqu'un client/le serveur reçoit un paquet, il va calculer la somme de contrôle en utilisant le même algorithme et comparer le résultat avec le champ checksum de votre paquet. Si les deux correspondent alors votre paquet n'a pas été corrompu par le réseau, sinon il faut ignorer le paquet (comme s'il avait été perdu, de toute façon il n'est pas exploitable).
Attention toutefois que ce mécanisme ne protège en aucune façon contre les attaques, uniquement contre les aléas du réseau. Rien n'empêche une personne malveillante de changer les données de votre paquet et de changer la somme de contrôle de celui-ci pour le faire paraître légitime.
Nous verrons dans le chapitre sur la sécurité comment assurer l'intégrité et l'authenticité d'un paquet d'une pierre deux coups grâce au chiffrement, nous protégeant à la fois contre la corruption disons "naturelle" (rendant donc un champ checksum redondant) et celle volontaire (d'un vilain à coeur).
La fiabilité
Le point central d'une couche de fiabilité étant justement la fiabilité, ceci est le point le plus important à aborder.
Reprenons, les paquets UDP sont aussi fiables que les paquets IP, c'est-à-dire qu'ils ne le sont pas du tout. Dans la grande majorité des cas les paquets que vous enverrez seront bien reçus par le destinataire, mais il peut arriver que ceux-ci arrivent dans le désordre, arrivent corrompus ou tout simplement n'arrivent jamais.
La corruption étant normalement gérée par votre somme de contrôle ou votre chiffrement (voir la partie juste au-dessus), il ne nous reste qu'à gérer les paquets arrivant dans le désordre, ceux arrivant dupliqués ou ceux n'arrivant jamais (ou simplement trop tard).
Tout d'abord, il va falloir faire la différence entre les données que vous voulez fiables (celles qui doivent arriver à destination quoiqu'il arrive), celles que vous voulez ordonner (celles dont l'ordre est important) et celles dont vous vous fichez qu'elles soient fiables, ordonnées ou les deux.
Personnellement je ne trouve pas beaucoup d'intérêt à pouvoir envoyer et recevoir des données non-ordonnées, donc je me concentre principalement sur l'aspect fiable ou non-fiable.
La première étape dans la fiabilité est donc de pouvoir reconnaître et ordonner les paquets dans le temps. Il va donc nous falloir deux compteurs de chaque côté de chaque connexion : un compteur incrémental pour chaque paquet envoyé et un nombre indiquant le numéro de séquence le plus élevé reçu.
Je vous recommande de partir sur des nombre non-signés de 16bits, dans la mesure où on va autoriser l'overflow (il serait dommage d'avoir une limitation sur le nombre de paquets qu'on peut envoyer) il nous faut une marge suffisamment grande entre la valeur la plus basse (0) et la valeur la plus haute (ici 2^16 -1 soit 65535 ou 0xFFFF en hexadécimal).
Initialisons donc ces deux nombres (encore une fois, de chaque côté) respectivement à la valeur minimale du compteur et à la valeur maximale du compteur :
outgoingSequenceNumber = 0 // Compteur d'émission
incomingSequenceNumber = 0xFFFF // "Compteur" de réception
À chaque fois que vous allez envoyer un paquet, vous allez intégrer la valeur de votre outgoingSequenceNumber dans votre paquet et l'incrémenter, cette valeur vous permet de partager l'ordre d'émission de vos paquets et assurer la bonne réception de l'autre côté.
Côté réception, lorsque nous recevons un paquet, que nous connaissons l'expéditeur ("Les connexions") et que nous sommes certains de l'intégrité de celui-ci ("L'intégrité de vos paquets") nous pouvons alors lire le numéro de séquence qu'il porte et le comparer à notre incomingSequenceNumber pour savoir s'il est plus récent (donc normalement plus grand, ou presque...).
En effet petite subtilité ici pour la comparaison : comme nous autorisons les compteurs à boucler (ceci pour éviter de se traîner une limite et limiter l'espace occupé par ces nombres), on ne peut pas se contenter de regarder si le nombre X est plus grand que Y.
Exemple : le paquet 1 est plus récent que le paquet 0, mais le paquet 0 est plus récent que le paquet 65332.
Pour s'en sortir, en plus de comparer les nombres nous allons également comparer leur distance (différence absolue), si le nombre A est plus grand que B et que leur distance est inférieure à la moitié de ce qui est représentable en 16bits (32768), alors c'est bon. Et du coup inversement si le nombre A est plus petit que B leur distance doit être supérieure à 32768.
En pseudo-code, ça donne ça :
func is_more_recent(uint16 a, uint16 b) -> bool
{
if (a > b)
return (a - b) <= 32768
else if (b > a)
return (b - a) > 32768
else
return false
}
Problème réglé !
Et donc, maintenant que l'on peut savoir qu'un numéro de paquet est plus récent qu'un autre, c'est très exactement ce que nous allons faire.
Reprenons donc l'exemple plus haut, vous recevez un paquet, validez son intégrité et identifiez son client. Vous allez ensuite décoder le numéro de séquence de ce paquet.
Si le numéro de séquence est plus vieux ou équivalent à la valeur incomingSequenceNumber nous allons l'ignorer, nous le considérerons comme un doublon d'un paquet déjà reçu.
Du coup, si le numéro de séquence que nous recevons est plus récent que incomingSequenceNumber, là il y a deux options :
- Soit le numéro de séquence reçu est équivalent à
incomingSequenceNumber + 1, ce qui signifie que c'est le paquet que nous attendions : on incrémenteincomingSequenceNumberet on transmet le paquet à l'application. - Soit le numéro de séquence reçu est plus grand que celui attendu (ce qui arrive en cas de retard ou perte du paquet attendu), alors on ne touche pas au compteur et on le met potentiellement dans une file d'attente[4].
Exemple :
Prenons deux personnes connectées, que nous nommerons Charles et Jérôme.[5] (Si ça peut vous aider, dites-vous que Jérôme est le serveur et Charles le client, mais ça ne change strictement rien).
Charles et Jérôme représentent chacun l'autre client avec des compteurs dans l'état par défaut :
outgoingSequenceNumber = 0
incomingSequenceNumber = 0xFFFF // 65535
Charles va envoyer trois paquets à Jérôme, ceux-ci auront donc les numéros de séquence 0, 1 et 2 à l'envoi.
Jérôme reçoit son premier paquet, celui portant le numéro de séquence 0, il va le comparer à son compteur de réception (incomingSequenceNumber), voir que 0 est plus récent que 65535 et qu'en prime, est le paquet attendu (uint16(65535) + 1 = 0 avec l'overflow), très bien. Jérôme met donc à jour son incomingSequenceNumber vers 0.
La file d'attente est interrogée pour savoir si le paquet 1 s'y trouve, mais non, on s'arrête là et on transmet le paquet à l'application.
Peu après, Jérôme reçoit le paquet portant le numéro de séquence 2, celui-ci est bien plus récent que 0 mais n'est pas équivalent à 0 + 1 = 1, il faut donc le mettre en file d'attente (à condition qu'il n'y soit pas déjà).
Aucun paquet n'est transmis à l'application et aucun compteur n'est touché.
Enfin, Jérôme reçoit le paquet portant le numéro de séquence 1, celui-ci possède les caractéristiques attendues : plus récent que 0 et équivalent à 0 + 1 = 1, parfait.
Ensuite, on interroge la file d'attente en boucle pour savoir si le paquet suivant s'y trouve, le paquet 2 s'y trouve mais pas d'éventuel paquet 3, on peut s'arrêter là.
Jérôme met donc à jour son incomingSequenceNumber sur la valeur 2 et envoie les paquets 1 et 2 à l'application.
Tout se passe au final très bien, on peut même s'amuser à rajouter des doublons de paquets à chaque étape sans que cela ne pose problème.
Tout va bien dans le meilleur des mondes.
Sauf si nous perdons un paquet.
Aïe, comment faire si Charles a bien envoyé le paquet 1 mais que, le réseau étant ce qu'il est, Jérôme ne le reçoit jamais ?
Pour régler ce problème, il nous faut un système d'accusé de réception. Jérôme doit prévenir Charles de la bonne réception de chacun de ses paquets, afin que l'absence d'accusé de réception provoque le renvoi du paquet en question.
Comment faire ça ? Pas trop le choix, pour prévenir l'expéditeur de la bonne réception de notre paquet il faut... lui renvoyer un paquet de confirmation.
Jérôme pourrait par exemple envoyer un paquet de confirmation contenant son incomingSequenceNumber à Charles à chaque fois qu'il le met à jour, et si au bout d'un certain temps (dépendant du ping[6]) Charles ne reçoit pas la confirmation de bonne réception d'un paquet, il le renvoie.
Sentez-vous un problème se dessiner ? Que se passe-t-il si le paquet de confirmation se perd ?
Une façon de s'en sortir est de faire en sorte que si nous recevons un paquet que nous avons déjà reçu, nous envoyons un nouveau paquet de confirmation de bonne réception (tout en ignorant le paquet).
De la sorte, si Jérôme ne reçoit pas le paquet 1, Charles finira par l'envoyer à nouveau. Et si le paquet 1 finit par arriver mais que la confirmation de réception se perd, Charles renverra le paquet 1 à Jérôme, qui ignorera le paquet (car il l'a déjà reçu) mais enverra de nouveau le paquet de bonne réception, et ce jusqu'à ce que le paquet de réception soit bien reçu.
Bon, tout cela fonctionne et est assez simple à implémenter, mais cela signifie faire transiter un nombre conséquent de paquets et avoir un temps de récupération (en cas de perte) assez conséquent, on doit pouvoir faire mieux.
Et en effet, en partant du principe que la communication est bi-directionnelle, c'est-à-dire que des paquets sont échangés régulièrement dans les deux sens, alors nous pouvons faire mieux. Il nous suffit d'intégrer le nombre du dernier paquet reçu dans l'en-tête de chacun des paquets qu'on envoie. Et si aucun paquet n'est envoyé pendant un certain temps[7] alors il suffit de forcer l'envoi d'un paquet "vide" (ne contenant que les en-têtes), ou bien même d'un paquet de ping.
La bibliothèque reliable.io, que je ne peux que vous recommander pour gérer la fiabilité dans votre propre protocole, utilise une technique encore plus intelligente : chaque paquet envoyé contient dans son en-tête, en plus du dernier numéro de séquence reçu, un nombre 32bits dont chaque bit indique la bonne réception (ou non) des 32 paquets précédents (par exemple si le dernier numéro de séquence reçu est 42, alors le premier bit indique si le paquet 41 a été reçu ou non, le second bit le paquet 40, etc.).
Je ne pourrais jamais assez vous recommander de lire les articles de Glenn Fiedler (en anglais), l'auteur de reliable.io et yojimbo, sur le sujet si vous souhaitez implémenter ces mécanismes vous-mêmes.
Petite note de bas de page : faites la différence entre les paquets de votre protocole et les paquets UDP. En effet si vous avez beaucoup de paquets de petite taille à envoyer sur le réseau en même temps, il sera bénéfique de les regrouper en un seul paquet UDP.
En conclusion
Vous l'aurez compris, concevoir son propre protocole par-dessus UDP n'est pas une mince affaire, mais ce tutoriel aborde les trois principes clés vous permettant d'arriver à quelque chose de fonctionnel.
Je vous conseille grandement de prendre le temps qu'il faut sur cette partie qui est la plus importante dans la conception de ce genre de protocole, tout ce qui va suivre ensuite est principalement constitué d'améliorations mais ça ne sert à rien d'améliorer quelque chose qui ne fonctionne pas. :D
Alors évidemment tester votre protocole en local ne vous apportera aucun indice sur sa viabilité, et même le tester sur Internet ne vous permettra pas de voir tous les problèmes potentiels survenir. C'est pour ça que je vous recommande d'utiliser un logiciel pour simuler de la latence, de la perte, duplication et corruption de paquet.
Celui que j'utilise est Clumsy.
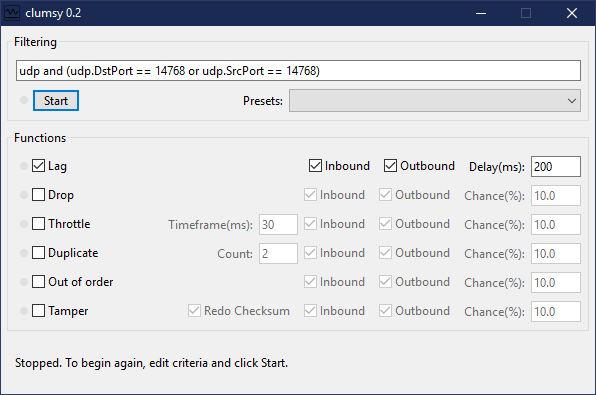
Ce logiciel, simple mais puissant, ne fonctionne que sur Windows. Si vous êtes sur un autre système il existe des alternatives, listées sur la page de présentation de Clumsy.
Dans le prochain chapitre nous discuterons de la taille maximale des paquets UDP (pour l'instant limitez vos paquets à 1400 octets) et des problèmes de congestion qui peuvent survenir lorsque vous surchargez la connexion en terme de réseau.
Il est possible d'avoir plusieurs sockets UDP en écoute sur le même port (voir SO_REUSEPORT). Cela fera du load balancing pour que chaque socket reçoive à peu près le même nombre de paquets, vous permettant d'augmenter potentiellement la paraléllisation de votre serveur (je vous conseille fortement néanmoins de ne pas vous en occuper pour l'instant). ↩︎
Il est important d'utiliser le port pour identifier un expéditeur, il peut arriver que plusieurs clients possèdent la même adresse IP (ex: même box/connexion mobile) et le port de réponse sera alors votre seul moyen de les différencier en tant que destinataires sur le réseau. ↩︎
N'oubliez pas que vous allez probablement transmettre un nombre non-négligeable de paquets, et que même une très faible probabilité comme la perte, corruption ou autre souci va se produire, la vraie question étant plutôt "quand ?". ↩︎
Cette file d'attente consiste simplement en un tableau de paquets reçus et considérés en attente jusqu'à la réception du paquet attendu. Chaque numéro de séquence ne peut être en attente qu'une seule fois (si vous attendez le numéro 13 et que vous recevez deux fois le numéro 14, ne mettez que le premier en attente). Je vous conseille également de fixer une limite sur le nombre de paquets pouvant être mis en attente pour éviter d'allouer des ressources inutiles, ignorez les paquets dont le numéro dépasse un certain seuil (arbitraire, disons 100) par rapport au dernier paquet reçu. ↩︎
Toute ressemblance avec des personnes existantes ou ayant existé serait purement fortuite. ↩︎
Le ping est le temps moyen que vous mettez entre l'envoi d'un paquet et la réception du paquet de confirmation pour ce paquet-là, autrement dit le temps moyen d'un aller-retour sur le réseau. ↩︎
Ce temps doit être assez court et ne pas excéder le temps avant qu'un expéditeur ne bloque l'envoi de paquet sans confirmation de bonne réception. ↩︎