TSOM : Les bases d'un voxel engine
Les bases du voxel engine de This Space Of Mine, ou comment sont gérés rendus et physique.

Hello !
Ça faisait un moment que je voulais faire un petit journal de développement autour de mon projet de jeu actuel : This Space Of Mine, ou TSOM (GitHub).
Il s'agit d'un jeu de construction et d'exploration spatial basé sur des voxels qui - pour le moment - ressemble beaucoup à un "Minecraft dans l'espace" (j'utilise un pack d'asset gratuit comme textures placeholder pour l'instant donc c'est compliqué de vous donner tort).
La planète que vous voyez, même si elle semble petite par rapport à un monde de Minecraft, représente pas loin de quatre millions de blocs.
Et comme notre carte graphique en rendu classique ne supporte que des triangles, nous devons lui en générer.
Si on part du principe qu'un bloc de six faces compte douze triangles, ça nous ferait pas loin de 48 millions de triangles si on les affichait tous.
Alors vous allez me dire que tous ces blocs ne sont pas pleins et effectivement, les blocs vides (à la surface de la planète) ne sont pas affichés.
Mais ça nous laisse quand même quelques dizaines de millions de triangles en trop.
D'autres solutions parlent d'utiliser le GPU instancing pour afficher plus rapidement les cubes[1], une technique permettant de rendre plus rapidement plusieurs fois le même objet, mais il y en a juste trop.
Alors comment améliorer ça ? C'est là qu'un "voxel engine" entre en jeu.
Voxel Engine
Un voxel engine est en réalité un algorithme assez simple, l'idée est de ne générer que les faces qui peuvent être visibles, autrement dit qui ne sont pas cachées par le bloc voisin.
On va donc, au lieu de faire une entité/un objet affichable par bloc, faire une gigantesque entité pour la planète avec un mesh créé sur mesure selon notre grille de blocs.
En mémoire, on peut donc représenter notre grille de blocs telle quelle, avec une succession d'uint8 ou d'uint16 (selon le nombre de blocs différents que vous avez), ça peut paraître énorme mais ça ne représente que 4 ou 8 mégaoctet pour toute la planète.[2]
Lorsqu'on va générer le mesh (et donc les triangles), l'idée est de parcourir chaque bloc et de regarder dans chaque direction si un voisin est présent ou non pour savoir si nous devons générer la face.
Dans TSOM, cela ressemble à ceci :
for (unsigned int z = 0; z < m_size.z; ++z)
{
for (unsigned int y = 0; y < m_size.y; ++y)
{
for (unsigned int x = 0; x < m_size.x; ++x)
{
BlockIndex blockIndex = GetBlockContent({ x, y, z });
if (blockIndex == EmptyBlockIndex)
continue;
Nz::EnumArray<Nz::BoxCorner, Nz::Vector3f> corners = ComputeVoxelCorners({ x, y, z });
Nz::Vector3f blockCenter = std::accumulate(corners.begin(), corners.end(), Nz::Vector3f::Zero()) / corners.size();
// Up
if (auto neighborOpt = GetNeighborBlock({ x, y, z }, { 0, 0, 1 }); !neighborOpt || neighborOpt == EmptyBlockIndex)
DrawFace(blockIndex, blockCenter, { corners[Nz::BoxCorner::RightTopNear], corners[Nz::BoxCorner::LeftTopNear], corners[Nz::BoxCorner::RightBottomNear], corners[Nz::BoxCorner::LeftBottomNear] });
// Down
if (auto neighborOpt = GetNeighborBlock({ x, y, z }, { 0, 0, -1 }); !neighborOpt || neighborOpt == EmptyBlockIndex)
DrawFace(blockIndex, blockCenter, { corners[Nz::BoxCorner::LeftTopFar], corners[Nz::BoxCorner::RightTopFar], corners[Nz::BoxCorner::LeftBottomFar], corners[Nz::BoxCorner::RightBottomFar] });
// Front
if (auto neighborOpt = GetNeighborBlock({ x, y, z }, { 0, -1, 0 }); !neighborOpt || neighborOpt == EmptyBlockIndex)
DrawFace(blockIndex, blockCenter, { corners[Nz::BoxCorner::RightTopFar], corners[Nz::BoxCorner::RightTopNear], corners[Nz::BoxCorner::RightBottomFar], corners[Nz::BoxCorner::RightBottomNear] });
// Back
if (auto neighborOpt = GetNeighborBlock({ x, y, z }, { 0, 1, 0 }); !neighborOpt || neighborOpt == EmptyBlockIndex)
DrawFace(blockIndex, blockCenter, { corners[Nz::BoxCorner::LeftTopNear], corners[Nz::BoxCorner::LeftTopFar], corners[Nz::BoxCorner::LeftBottomNear], corners[Nz::BoxCorner::LeftBottomFar] });
// Left
if (auto neighborOpt = GetNeighborBlock({ x, y, z }, { -1, 0, 0 }); !neighborOpt || neighborOpt == EmptyBlockIndex)
DrawFace(blockIndex, blockCenter, { corners[Nz::BoxCorner::RightBottomNear], corners[Nz::BoxCorner::LeftBottomNear], corners[Nz::BoxCorner::RightBottomFar], corners[Nz::BoxCorner::LeftBottomFar] });
// Right
if (auto neighborOpt = GetNeighborBlock({ x, y, z }, { 1, 0, 0 }); !neighborOpt || neighborOpt == EmptyBlockIndex)
DrawFace(blockIndex, blockCenter, { corners[Nz::BoxCorner::LeftTopNear], corners[Nz::BoxCorner::RightTopNear], corners[Nz::BoxCorner::LeftTopFar], corners[Nz::BoxCorner::RightTopFar] });
}
}
}
(Attention au nommage, DrawFace ne dessine pas à proprement parler, mais génère les indices et vertices pour cette face, cette opération n'est donc faite qu'à la génération du mesh).
Bref, rien de bien sorcier mais ceci permet de réduire drastiquement le nombre de triangles générés et affichés, on arrive donc à 230'636 triangles, soit moins d'1% par rapport au nombre de triangles d'origine !
En revanche nous nous retrouvons confrontés à plusieurs problèmes, du fait que nous ayons un seul gros mesh.
Pour commencer, l'affichage ne fonctionne qu'en "tout ou rien", les techniques dites de culling (déterminant si une entité est visible avant d'ordonner affichage à la carte graphique) sont inefficaces car il suffira qu'un petit bout de la planète soit visible à l'écran pour intimer l'ordre à la carte graphique de rendre plusieurs centaines de milliers de triangles.
Ensuite, pas de LOD[3] partiel possible, soit la planète entière est en haute définition soit la planète entière est en basse définition.
Dernier point, et non des moindres, la génération prend du temps. Imaginez votre CPU générer le mesh de toute la planète dès que vous posez ou enlevez le moindre petit bloc durant plusieurs secondes (oui) à chaque fois.
Bref, pas vraiment idéal.
Diviser pour mieux régner
La solution à ce problème consiste à ne pas avoir une seule grosse grille de blocs mais plusieurs grilles plus petites, ayant chacune un offset de position.
On peut subdiviser la planète ensuite sur les trois axes par un nombre de blocs dans ce qu'on appelle les "chunks" (oui, comme ce fameux jeu de minage et crafting).
Dans mon cas j'ai choisi comme taille de grille 32x32x32, soit un total de 32768 blocs par chunk.
Gérer ceci par chunks élimine les trois défauts plus haut[4] et nous donne des avantages supplémentaires :
- Notre grille devient extensible, en donnant des indices signés à chaque chunk nous pouvons l'étendre dans toutes les directions, permettant aux joueurs de construire des grattes-ciels en créant des chunks à la volée.
- Nous pouvons charger et simuler une partie de la planète (proches de là où le joueur se trouve), et sauvegarder sur le disque les chunks inactifs.
- Nous pouvons paralléliser la génération des chunks, pour générer la planète entière beaucoup plus rapidement (par exemple à la connexion du joueur).
À noter que l'instancing ne résoudrait rien, c'est une technique peu efficace sur un petit nombre de triangles. ↩︎
Il existe des techniques de compression permettant de consommer moins de mémoire mais ce n'est pas important à ce stade. ↩︎
Level Of Detail, une technique consistant à décroitre la qualité d'un mesh en fonction de sa distance. une vidéo sympa à ce sujet. ↩︎
Et nous permet même de l'occlusion culling, où nous pouvons détecter qu'un chunk se situe devant d'autres chunks et que nous n'avons pas besoin d'afficher ceux derrière). ↩︎
Dans This Space Of Mine, les chunks sont générés de façon asynchrone et multithreadée, que ça soit pour la génération procédurale ou la génération du mesh.
Pour ce faire, j'exploite le TaskScheduler de Nazara, une threadpool à qui je peux donner du travail qui sera ensuite exécuté sur plusieurs threads :
void Planet::GenerateChunks(const BlockLibrary& blockLibrary, Nz::TaskScheduler& taskScheduler, Nz::UInt32 seed, const Nz::Vector3ui& chunkCount)
{
for (int chunkZ = 0; chunkZ < chunkCount.z; ++chunkZ)
{
for (int chunkY = 0; chunkY < chunkCount.y; ++chunkY)
{
for (int chunkX = 0; chunkX < chunkCount.x; ++chunkX)
{
auto& chunk = AddChunk({ chunkX - int(chunkCount.x / 2), chunkY - int(chunkCount.y / 2), chunkZ - int(chunkCount.z / 2) }); // indices du chunk
taskScheduler.AddTask([&]
{
GenerateChunk(blockLibrary, chunk, seed, chunkCount);
});
}
}
}
// On attend que toutes les tâches précédentes soient exécutées
taskScheduler.WaitForTasks();
}
Ici j'ai donc 125 tâches réparties sur les 32 threads de mon processeur, chaque chunk est généré avec la même seed mais connait son décalage par rapport à l'origine, permettant une génération continue même d'un chunk à l'autre (j'utilise un bruit de perlin classique pour l'instant).
Le mesh sera ensuite généré dès qu'il en aura besoin mais sans bloquer le jeu. C'est intéressant car même si nos chunks se génèrent bien plus rapidement que la planète, un freeze pourrait être perceptible (surtout si plusieurs chunks sont modifiés simultanément[1]).
Nous partons dès lors du principe qu'un chunk peut être accédé par plusieurs threads, le thread principal (de jeu) qui va vouloir notamment le modifier (place/enlève un bloc) et les threads du TaskScheduler qui vont vouloir le lire lors de la génération, les deux ne doivent pas se produire en même temps.
Nous allons donc simplement ajouter une mutex à chaque chunk, permettant à un thread de verrouiller sa mémoire, lorsque nous le modifions :
m_onChunkUpdate.Connect(stateData.sessionHandler->OnChunkUpdate, [&](const Packets::ChunkUpdate& chunkUpdate)
{
Chunk* chunk = m_planet->GetChunkByNetworkIndex(chunkUpdate.chunkId);
chunk->LockWrite();
for (auto&& [blockPos, blockIndex] : chunkUpdate.updates)
chunk->UpdateBlock({ blockPos.x, blockPos.y, blockPos.z }, Nz::SafeCast<BlockIndex>(blockIndex));
chunk->UnlockWrite();
});
et lorsque nous le générons :
std::shared_ptr<ColliderModelUpdateJob> updateJob = std::make_shared<ColliderModelUpdateJob>();
updateJob->taskCount = 2;
updateJob->applyFunc = [this](const ChunkIndices& chunkIndices, UpdateJob&& job)
{
// Changement du mesh sur l'entité
// [...]
};
taskScheduler.AddTask([this, chunk, updateJob]
{
chunk->LockRead();
updateJob->collider = chunk->BuildCollider(m_blockLibrary);
chunk->UnlockRead();
updateJob->jobDone++;
});
taskScheduler.AddTask([this, chunk, updateJob]
{
chunk->LockRead();
updateJob->mesh = BuildMesh(chunk);
chunk->UnlockRead();
updateJob->jobDone++;
});
m_updateJobs.insert_or_assign(chunk->GetIndices(), std::move(updateJob));
Remarquez au passage la façon dont je m'y prends pour générer le mesh de façon asynchrone mais que j'applique le changement dans le thread principal, via des jobs disposant d'un compteur de tâche (atomique) à effectuer.
À chaque tour de boucle, le thread principal vérifie pour chaque job si le compteur de tâche a atteint le nombre total de tâches, et lorsque c'est le cas appelle applyFunc (qui ici change le mesh affiché).
Remarquez aussi que nous avons ici de la physique qui est générée en parallèle, dont je parlerais plus en détail un peu plus loin dans l'article, mais cela signifie que le contenu d'un chunk peut être lu par deux threads (et plus) de façon simultanée.
Une mutex classique serait très inefficace car elle bloquerait la génération du mesh tant que la génération de la physique n'est pas effectuée et inversement, nous utilisons donc une std::shared_mutex. Celle-ci autorise plusieurs threads à la verrouiller en lecture simultanément sans bloquer, mais si un thread verrouille en écriture il sera le seul propriétaire.
Plusieurs threads peuvent donc accéder en même temps au contenu d'un chunk pour le lire, mais un seul peut le modifier. Idéal dans notre cas.
Bien, regardons ce que ça donne !
Au même tick, que ça soit par plusieurs joueurs ou par un événement à large zone, comme des explosions sur Minecraft. ↩︎

Super, regardons maintenant le nombre de triangles.
triangle count: 759292
Ouch.
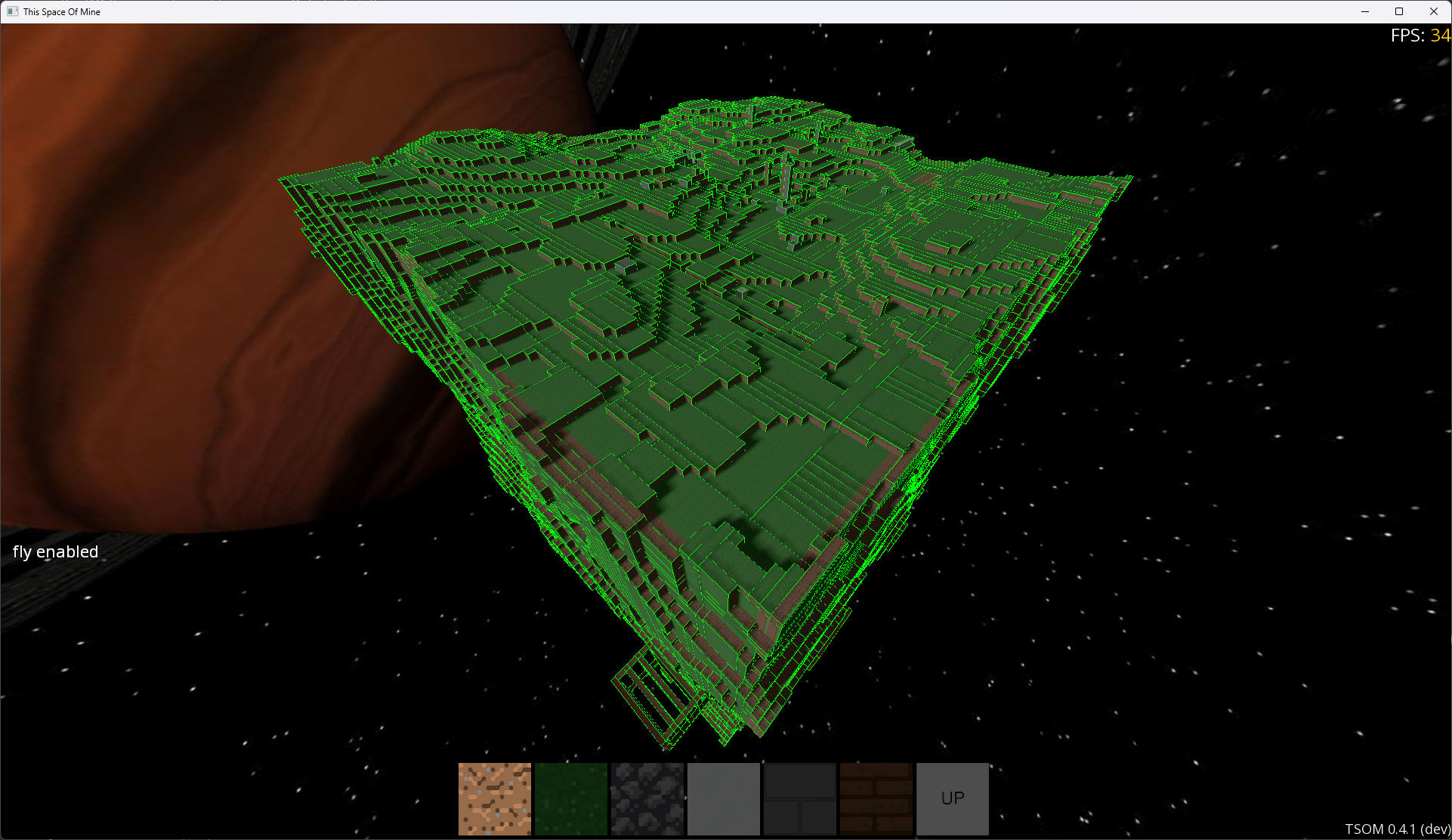
Nous avons plus que triplé notre nombre de triangles, que s'est-il passé ?
Regardons un mesh d'un chunk plus en détail :

Effectivement, comme chaque chunk est indépendant et ne s'occupe que de sa grille, il considère ses frontières comme entourées de vide et génère donc les faces entre les chunks.
Il est facile d'y remédier, lorsque nous cherchons le bloc voisin, autorisons-nous à chercher dans les chunks d'à côté pour savoir si nous devons générer ou non la face.
Afin d'avoir une génération cohérente entre le chunk et ses voisins, verrouillons tous les voisins en lecture au début de la génération du chunk[1].
// Find and lock all neighbor chunks to avoid discrepancies between chunks
Nz::EnumArray<Direction, const Chunk*> neighborChunks;
for (auto&& [dir, chunk] : neighborChunks.iter_kv())
{
chunk = m_owner.GetChunk(m_indices + s_dirOffset[dir]);
if (!chunk)
continue;
chunk->LockRead();
}
// On oublie pas de libérer le verrou à la fin, peu importe comment on sort de la fonction
NAZARA_DEFER(
{
for (const Chunk* chunk : neighborChunks)
{
if (chunk)
chunk->UnlockRead();
}
});
Lorsque nous allons chercher le voisin d'un bloc dans une direction, nous pouvons donc taper dans le chunk d'à côté.
Vérifions si cela fonctionne ...
Pour l'instant nous ne considérons pas les diagonales, mais lorsque nous générerons l'ambient occlusion il faudra considérer l'ensemble des 26 voisins. ↩︎

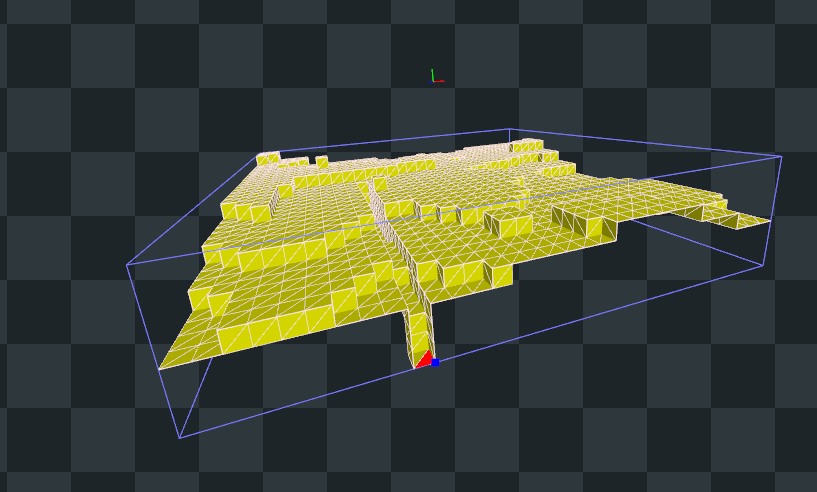
triangle count: 230636
Beaucoup mieux ! Avons-nous terminé ?
Malheureusement non, il nous reste un cas à gérer, admettons qu'un joueur décide de creuser un petit tunnel droit, que se passera-t-il au moment où il atteindra la limite d'un chunk ?
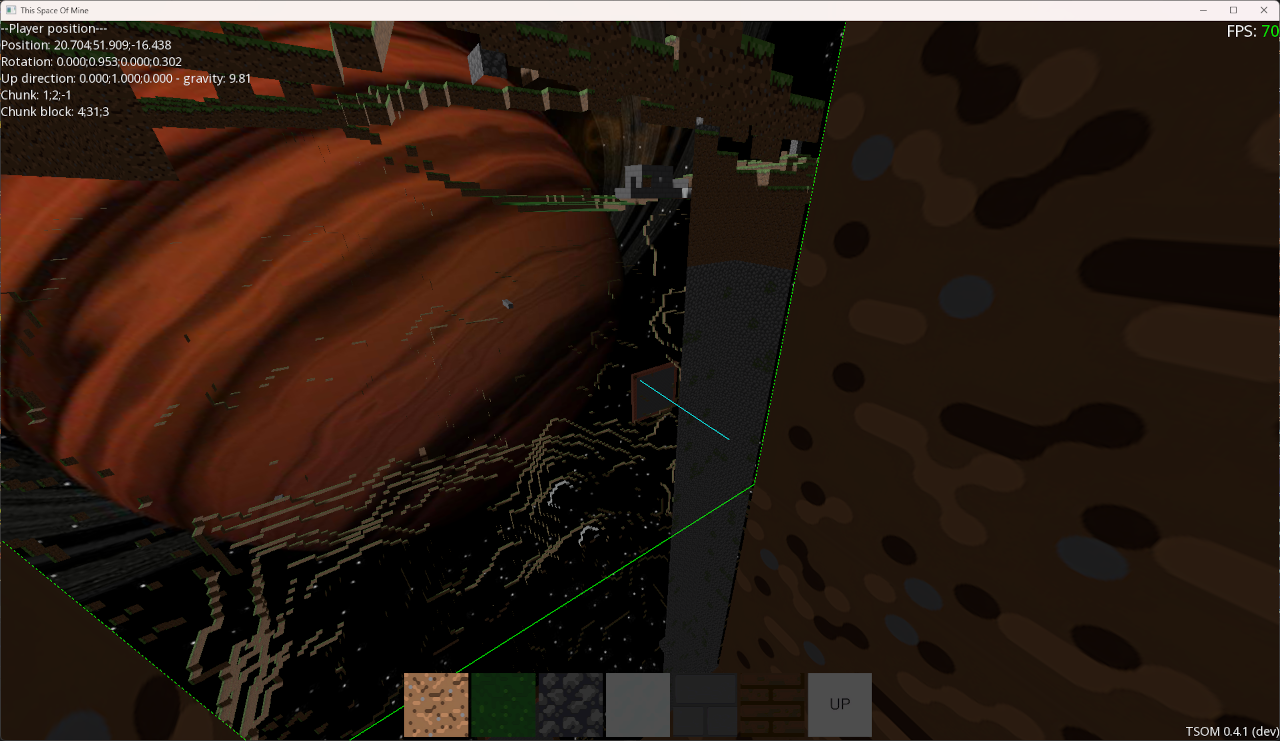
En effet, chaque chunk étant mis à jour de façon indépendante, le chunk voisin ne génèrera pas de face automatiquement pour nous dans ce cas.
Pour régler ce problème nous allons mettre à jour le (ou les) chunk voisin en cas de besoin.
Détectons déjà, à l'aide d'un masque, ce que nous avons besoin de mettre à jour :
chunkData.onUpdated.Connect(chunkData.chunk->OnBlockUpdated, [this](Chunk* chunk, const Nz::Vector3ui& indices, BlockIndex /*newBlock*/)
{
DirectionMask neighborMask;
if (indices.x == 0)
neighborMask |= Direction::Left;
else if (indices.x == chunk->GetSize().x - 1)
neighborMask |= Direction::Right;
if (indices.y == 0)
neighborMask |= Direction::Front;
else if (indices.y == chunk->GetSize().y - 1)
neighborMask |= Direction::Back;
if (indices.z == 0)
neighborMask |= Direction::Up;
else if (indices.z == chunk->GetSize().z - 1)
neighborMask |= Direction::Down;
OnChunkUpdated(this, chunk, neighborMask);
});
Nous accumulons ensuite les flags (tout en créant l'entrée si ce n'est pas déjà fait):
m_onChunkUpdated.Connect(chunkContainer.OnChunkUpdated, [this](ChunkContainer* /*emitter*/, Chunk* chunk, DirectionMask neighborMask)
{
m_invalidatedChunks[chunk->GetIndices()] |= neighborMask;
});
Cela permet de gérer le cas où plusieurs blocs sont mis à jour lors de la même update.
Et enfin lorsque nous traitons la mise à jour d'un chunk, nous allons également déclencher la mise à jour des chunks voisins si nécessaire.
Attention néanmoins, il ne suffit pas de juste demander au voisin de se mettre à jour, si nous faisions ça il pourrait arriver que le chunk modifié (sans bloc) soit mis à jour avant le chunk voisin, faisant apparaître pendant une fraction de seconde la face manquante.
Pour régler ce problème, nous introduisons une dépendance sur la mise à jour, nous n'autorisons l'application des modifications que lorsque tous les chunks dont nous dépendons ont terminés leur mise à jour.
Cela fonctionne dans les deux sens, si les deux chunks ont été modifiés au même moment, ils dépenderont l'un de l'autre pour appliquer leur modification.
// Add neighbor chunks
for (Direction neighborDir : neighborMask)
{
ChunkIndices neighborIndices = chunk->GetIndices() + s_dirOffset[neighborDir];
const Chunk* neighborChunk = m_chunkContainer.GetChunk(neighborIndices);
if (!neighborChunk || !neighborChunk->HasContent())
continue;
updateJob->chunkDependencies.push_back(neighborIndices);
// Trigger our neighbor update
if (!m_updateJobs.contains(neighborIndices))
ProcessChunkUpdate(neighborChunk, 0);
}
m_updateJobs.insert_or_assign(chunk->GetIndices(), std::move(updateJob));
Et lors du test :
for (auto it = m_updateJobs.begin(); it != m_updateJobs.end(); ++it)
{
UpdateJob& job = *it->second;
if (!job.HasFinished())
continue;
bool canExecute = true;
for (auto depIt = job.chunkDependencies.begin(); depIt != job.chunkDependencies.end();)
{
auto depJobIt = m_updateJobs.find(*depIt);
if (depJobIt == m_updateJobs.end())
{
// (je n'ai effectivement pas encore de vrai système de log)
fmt::print(fg(fmt::color::red), "update job for chunk {};{};{} depends on chunk {};{};{} which has not been added\n", it->first.x, it->first.y, it->first.z, depIt->x, depIt->y, depIt->z);
depIt = job.chunkDependencies.erase(depIt);
continue;
}
if (depJobIt->second->HasFinished())
{
depIt = job.chunkDependencies.erase(depIt);
continue;
}
canExecute = false;
++depIt;
}
if (canExecute)
{
job.applyFunc(it->first, std::move(job));
// Don't remove jobs immediatly to be able to detect dependencies errors
m_finishedJobs.push_back(it->first);
}
}
Et voilà, lorsque nous modifions un bloc en bordure de chunk, celui-ci va déclencher et dépendre des modifications de ses voisins avant de pouvoir se mettre à jour, sans enlever le fait que tout ça s'effectue en parallèle.
Maintenant nous avons fini, du moins pour le rendu.
Aller plus loin
Il est possible d'aller plus loin pour réduire le nombre de triangles affichés.
Un mesh par direction
Une technique serait de séparer l'index buffer en six groupes, un par direction. Ceci nous permettrait de ne pas afficher les faces qui sont orientées dans une direction similaire à la caméra (et que nous ne pourrions pas voir de toute façon sans la tourner), permettant de diviser par deux le nombre de triangles affichés.
Cette approche pourrait améliorer les performances mais dans le cas de TSOM les chunks peuvent subir une déformation liée à la gravité (pour arrondir les coins de la planète) - pas visible dans les screenshots plus haut - qui complique l'approche.
Fusionner les triangles
Lorsque nous avons par exemple quatre faces côte à côte avec la même texture, au lieu d'afficher huit triangles nous pourrions n'en afficher que deux, en ajustant les coordonnées de textures (en mode répétition).

Je ne compte pas implémenter cette technique pour le moment, elle rajouterait du coût de génération du chunk pour un gain pas forcément évident (le nombre de triangles n'est pas si important), tout en n'étant pas compatible avec la déformation de chunks et certains rendus (par exemple en alternant la rotation de la face pour éviter la répétition).
Tant que je ne sais pas exactement à quoi je veux que le jeu ressemble (et donc les contraintes de rendu), je ne partirais donc pas dessus.
Occlusion culling
On peut partir du principe que les chunks les plus proches du joueur (par exemple les 9 chunks les plus proches du joueur) vont représenter l'essentiel des pixels générés, et que les autres chunks seront minoritaires et même complètement cachés.
On peut donc partir sur un test d'affichage, où on rend dans un depth buffer les chunks les plus proches puis on rend la bounding box des chunks plus éloignés en comptant le nombre de pixels passant (grâce à une GPU query), si aucun pixel ne passe le test on sait que le rendu du chunk est inutile.
Je compte implémenter cette technique plus tard, quand j'aurais décidé de repasser sur le rendu et de prendre un peu plus le contrôle du pipeline (à l'aide de quelques compute shaders).
Les collisions
Gérer les collisions dans un Voxel Engine peut se faire de plusieurs façons.
Par exemple on pourrait directement mapper une position vers un bloc de notre grille et regarder s'il est plein ou pas, nous permettant très rapidement de savoir s'il y a collision ou non. Technique qui peut facilement être étendue vers des tests AABB/AABB qui sont très rapides (Minecraft exploite une technique de ce genre).
Dans TSOM j'exploite directement un moteur physique (Jolt Physics) et je prévois des interactions plus complexes. Je vais donc utiliser des ensembles de BoxShape pour gérer les collisions comme décrit ici par l'auteur de Jolt[1].
Un collider par bloc plein est possible, mais ...
La solution idéale serait probablement de faire une custom shape reprenant la logique AABB, ce que je ferais peut-être par la suite. ↩︎
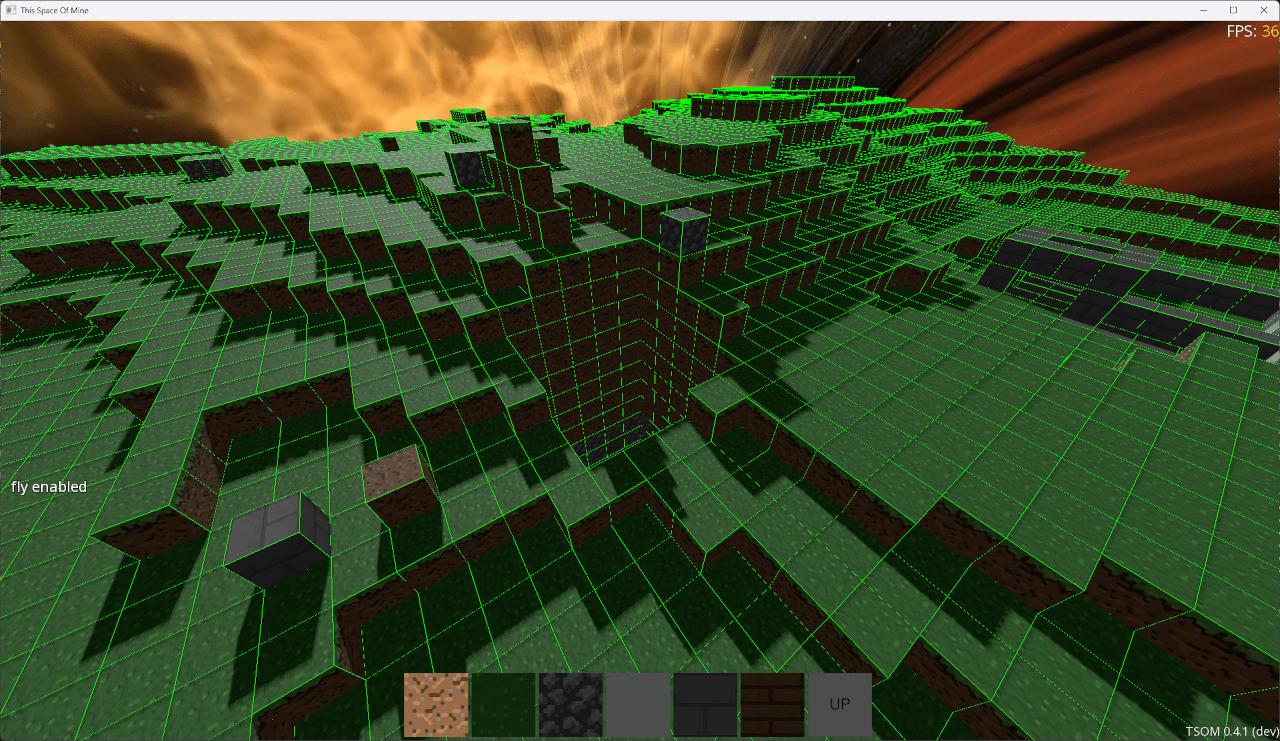
Jolt Physics a beau être un moteur très performant, cette approche est hautement inefficace.
À la place on va faire du Greedy Meshing[1], on va essayer de fusionner les blocs pleins adjçacents. L'algorithme est encore une fois assez simple : au lieu de générer un collider par bloc, on va mémoriser le point de départ et avancer jusqu'à ce que le bloc soit vide ou qu'on ait atteint la bordure.
Une fois que c'est le cas, on génère un collider entre notre point de départ et notre point d'arrivée en X-1, on essaie ensuite de l'agrandir en Z en regardant si tous les blocs à côté nécessitent des collisions, et puis finalement on essaie d'agrandir en Y en vérifiant que tous les blocs existent également sur cet axe.
Lorsqu'un bloc fait partie d'un collider, on ne l'autorise plus à faire partie d'un nouveau collider (ceci est fait à l'aide d'un bitset).
Mon implémentation est assez naïve mais donne un résultat suffisant. Néanmoins si vous souhaitez pousser plus loin on m'a recommandé cette vidéo.
Et voici le résultat :
Un article à ce sujet ↩︎
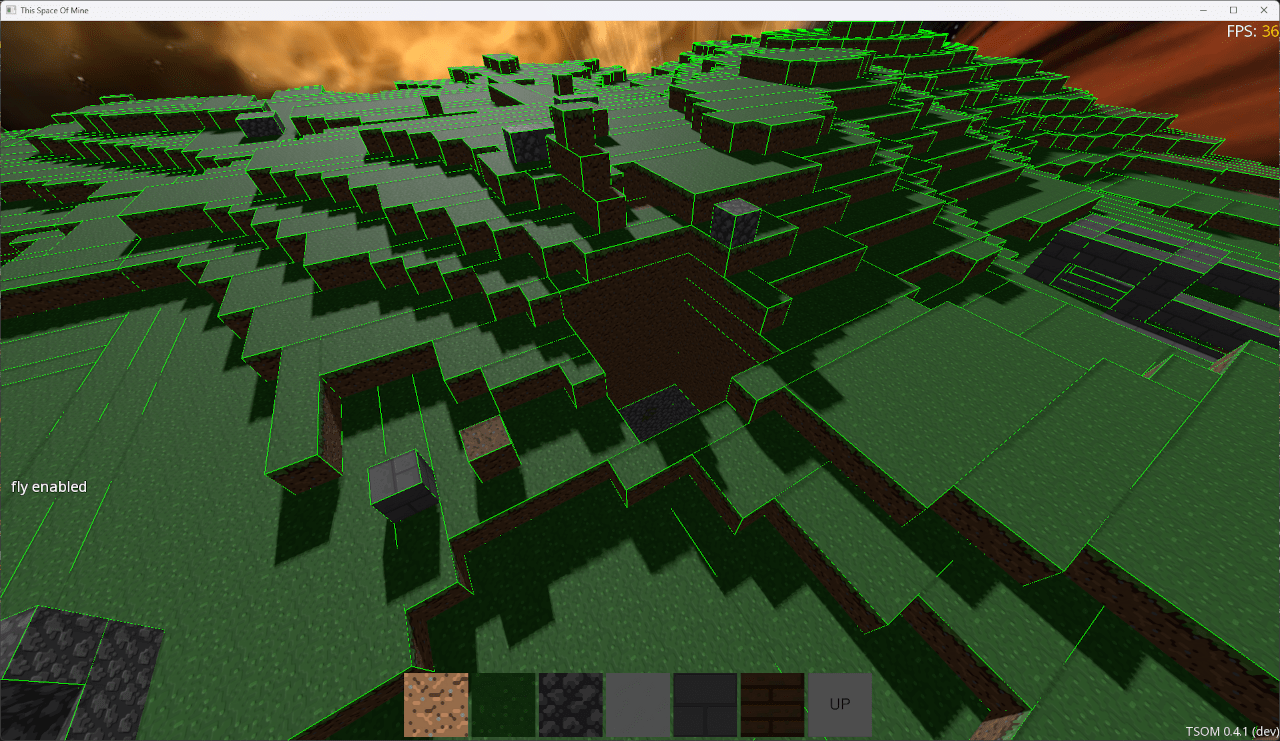
(Notez que les FPS n'ont pas bougé parce que ce qui prend le plus de temps c'est le rendu wireframe de tous les colliders, en debug).
Pour un chunk entièrement plein (comme à l'intérieur de la planète), on se retrouve donc avec un seul BoxShape d'une taille de 32x32x32 unités.
Notez que je n'essaie pas d'étendre les collisions au-delà des limites d'un chunk, cela complexifierait pas mal l'implémentation (théoriquement un box shape pourrait s'étendre sur une infinité de chunks) pour un gain pas forcément évident.
Conclusion
Voilà qui fait le tour de la façon dont je gère les voxels et les chunks dans TSOM, j'espère que vous avez apprécié cet article.
Ça fait un moment que je voulais écrire des articles / un devblog sur TSOM, mais je manque de volonté pour combattre la flemme d'en écrire à chaque fois, donc n'hésitez pas à me suggérer des sujets concernant le jeu, dont le développement est sur Twitch !
Voici également un replay vidéo du stream où j'implémente l'élimination des faces entre les chunks : https://www.youtube.com/watch?v=Cqd6DegDwuE
À bientôt !